1. Triggers
Triggering is another important aspect of a monitoring application. There are several types of triggering regimes:
- Continuous (always) - analysis of each data point of a signal as soon as it appears. Required for the most critical systems. We do not consider these signals in the first place, as they require a tight integration with the logging system (such as Apache Spark Streams).
- Synchronous - analysis triggered at regular time intervals.
- Synchronous with the machine cycle - analysis executed in a certain part of a machine cycle (injection, ramp, squeeze, plateau, ramp-down).
- Asynchronous - analysis triggered when a PM event occurs (like FPA, QPS).
Figure below presents an example of triggers synchronized with machine cycle (earth current, voltage feelers, busbar or current lead) and specific events (quench heaters and diode lead resistance).
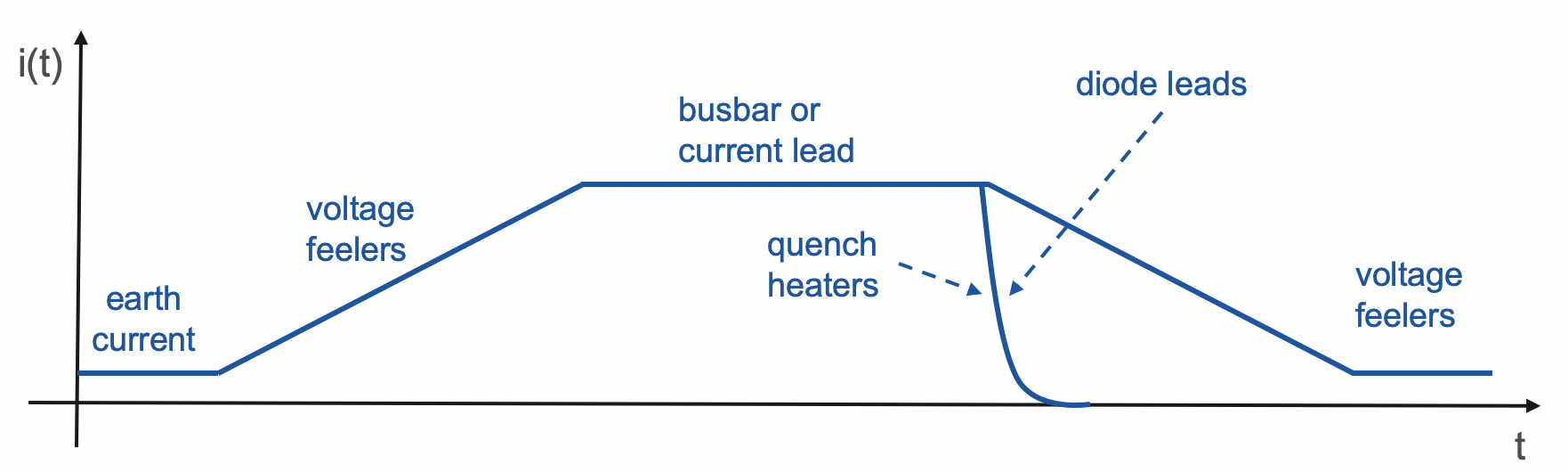
In case of analyses triggered by a machine cycle or asynchronous events there are two ways of receiving the trigger. One way is to regularly query a database in order to check the current beam mode and the presence of PM events. This approach results in increased load on the database. Another, more efficient approach, is to subscribe for events generated by hardware writing to the logging database. So far, we apply the first approach.
2. Workflow
The introduction of the NXCALS ecosystem calls for the revision of the infrastructure for execution of signal monitoring applications. The NXCALS not only changes an API for processing signals, but also promotes distributed storage and computation. SWAN service provides an environment for rapid prototyping of signal monitoring applications due to its tight integration with the NXCALS cluster. In addition, we developed SWAN notebooks for browsing of historical data stored in the NXCALS persistent storage. The last element is Apache Airflow for managing execution of signal monitoring applications. The full signal monitoring pipeline is depicted in Figure below.
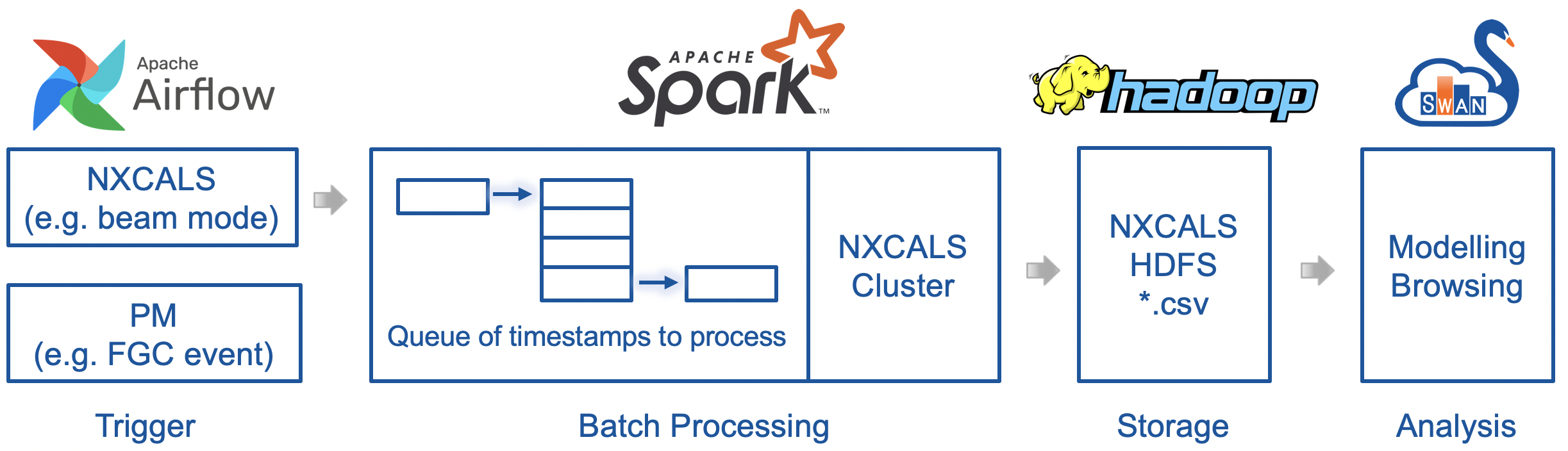
An Apache Airflow instance manages the process of batch processing of signal monitoring applications on the NXCALS cluster. The results of each application are stored in the HDFS persistent storage and browsed/- analysed further with dedicated SWAN notebooks.
Apache Airflow is a new component deserving an additional description. Although, the spark cluster allows submitting a computation in a batch mode and would retry its execution 8 times in case of failures, there is a need for a more customizable execution monitoring system. Apache Airflow allows for defining execution intervals, relations between jobs and managing notifications in case of failure. Note that Apache Airflow is not only suitable for triggering of monitoring applications, but also for execution of long-running jobs to gather historical data. Figure below shows a dashboard with several Airflow DAGs (Direct Acyclic Graphs) representing a batch process.